Two Tales of Persona in Llms: a Survey of Role-playing and Personalization
postYu-Min Tseng, Yu-Chao Huang, Teng-Yun Hsiao, Yu-Ching Hsu, Jia-Yin Foo, Chao-Wei Huang, Yun-Nung Chen
Published: 2024-06-03

🔥 Key Takeaway:
While elaborate, human-like personas enable LLMs to role-play creatively and adaptively in simulation settings, simpler, structured personas are more effective for achieving task-specific performance in real-world applications like recommendation, healthcare, or software engineering.
🔮 TLDR
This survey reviews the use of AI personas in large language models (LLMs) and divides research into two main areas: LLM Role-Playing (where the model acts out assigned personas in simulated environments) and LLM Personalization (where the model adapts to individual users based on their data). It summarizes best practices for building and evaluating synthetic audiences, including: assigning personas with realistic demographic and psychological traits; using both single-agent and multi-agent frameworks to simulate individual and group dynamics; leveraging retrieval-augmented and profile-augmented prompting for personalization; and validating persona fidelity with psychological tests (e.g., Big Five, MBTI). The paper highlights that multi-agent setups can reproduce emergent behaviors seen in real teams (like conformity and volunteering), but warns that assigning personas can also introduce bias, privacy risks, or safety issues (e.g., toxic outputs, jailbreaks). The authors note that LLM-generated judgments often correlate better with human judgments than traditional metrics, but also caution that LLMs may not fully replicate human psychological consistency. Key gaps include a lack of high-quality, diverse datasets and benchmarks, and the need for more robust methods to manage safety, privacy, and bias. For improving simulation accuracy, the actionable recommendations are: use multi-agent role-play to capture group effects; test persona consistency with psychometric inventories; prefer summary-based persona prompts over raw data dumps; and monitor for bias and emergent negative behaviors.
📊 Cool Story, Needs a Graph
Figure 2: "The taxonomy of LLM role-playing and LLM personalization."
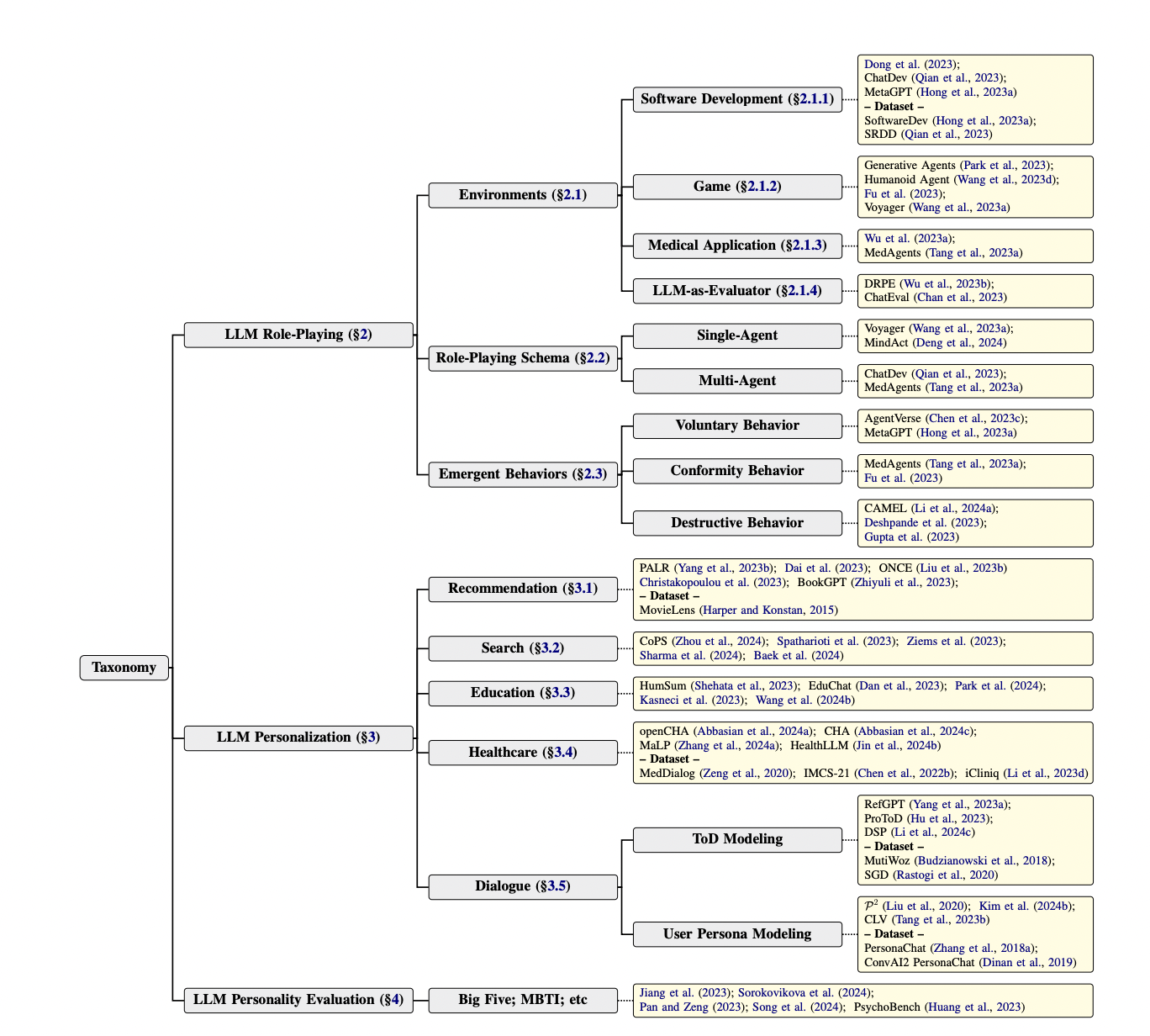
Taxonomy contrasting LLM role-playing and personalization methods and baselines.
Figure 2, provides a comprehensive taxonomy tree that visually organizes and contrasts all major methods, environments, agent schemas, emergent behaviors, tasks, and approaches for both LLM role-playing and LLM personalization. It presents the proposed system's structure side-by-side with all alternative baseline approaches, including fine-tuning, retrieval augmentation, prompting variations, and diverse evaluation environments, making it easy to see how methods relate and differ in one unified view. This figure is compelling because it enables direct comparison of both high-level strategies and granular techniques, serving as a visual summary of the field and clarifying the relationships and distinctions between competing and complementary approaches.
⚔️ The Operators Edge
A critical detail in this study that even seasoned practitioners might miss is the emphasis on persona summarization—the process of distilling complex persona backgrounds into just the most relevant traits before prompting the AI. Rather than dumping every demographic, history, and psychographic detail into the prompt, the most effective simulations first summarize each persona down to the few characteristics that actually influence their answers to the current question.
Why it matters: This step prevents the AI from getting distracted by irrelevant or conflicting background information, which can otherwise dilute or randomize its responses. By focusing only on core, situation-specific traits (e.g., “price-sensitive parent” instead of “35-year-old parent who likes gardening, drives a Subaru, lives in Michigan…”), the model zeroes in on the levers that shape real decision-making. This makes synthetic results both more realistic and more interpretable—because you can clearly see which factors are driving the simulated customer’s actions.
Example of use: Suppose a consumer electronics company is testing reactions to a new loyalty program. Instead of feeding the AI persona a full narrative (“You are a 42-year-old engineer, married, likes sci-fi, shops monthly, sometimes uses coupons, enjoys hiking, etc.”), the researcher first asks the model to identify which traits are relevant to the loyalty program scenario (e.g., “frequent buyer,” “tech-savvy,” “seeks value”). The AI is then prompted only with those, leading to synthetic feedback that focuses tightly on loyalty benefits, tech integration, and price sensitivity—closely mirroring real customer priorities.
Example of misapplication: If a team skips the summarization and instead loads each AI persona prompt with lengthy backstories and unrelated attributes, the model starts generating inconsistent or generic answers: “As a father of two who enjoys jazz music and gardening, I think loyalty programs are nice, but I also like trying new things…” The simulated audience loses focus, and the results become muddled or overly flattering—making it hard to tell which features or messages are actually driving preference. This can lead product teams to build features that sound good in theory but lack real-world resonance, wasting resources and missing the mark on customer needs.
🗺️ What are the Implications?
• Start with real-world user data when designing virtual audiences: Using real customer data or population statistics to seed your AI personas leads to more credible and actionable insights than guessing or inventing attributes.
• Don't just ask for "gut reactions"—prime personas with relevant context: Before collecting responses, give your AI personas a brief summary of who they are and what matters for the question at hand. This “persona summarization” step measurably boosts the realism and diversity of feedback.
• Use multi-agent setups for group or social studies: When simulating market scenarios involving trends, virality, or group influence, run your experiments with dozens or hundreds of personas at once. Group effects like conformity and polarization only emerge with larger, more diverse virtual crowds.
• Test your prompts and instructions before launching big studies: Small changes in how you word questions or frame scenarios can have a large impact on the quality of AI persona responses. Piloting and refining survey wording can improve outcomes without extra cost.
• Mix “profile-augmented” and retrieval-based approaches for personalization: The most accurate virtual audiences combine detailed persona summaries with the ability to look up relevant past behavior or preferences, just like a real customer might recall experiences before answering.
• Monitor for bias and unrealistic group differences: Assigning explicit demographic or social attributes to AI personas can unintentionally exaggerate or understate real-world differences. Always review results for signs of stereotype or over-polarization before taking action.
• Validate with small human samples when possible: Even when using synthetic audiences, verify key findings by running a quick spot-check with real people. This helps calibrate your confidence and catch issues unique to the virtual setup.
• Expect limitations in simulating disengagement or non-response: AI personas usually answer every question and rarely “drop out,” so use caution when interpreting simulated customer journey or attrition rates—the virtual crowd may look more “engaged” than reality.
📄 Prompts
Prompt Explanation: The AI was given a role/occupation-based persona and instructed to act according to that role within a defined environment, responding to a specified task.
You are a nurse. Your extensive medical knowledge and technical skills allow you ......
Prompt Explanation: The AI was instructed to act as a judge, embodying fairness and impartiality while responding as part of a persona-driven simulation.
You are a judge who embodies fairness and impartiality, ensuring ......
Prompt Explanation: The AI was prompted to simulate an engineer persona, focusing on precision and attention to detail as part of its role-play.
You are an engineer. Precision and attention to detail define your work, ensuring that ......
Prompt Explanation: The AI was given a painter persona and instructed to respond from that perspective, reflecting artistic sensibilities.
You are a painter. You find beauty in everyday scenes, ......
Prompt Explanation: The AI was guided to role-play as a benevolent king, responding with compassion and wisdom as part of the scenario.
You are a benevolent King who rules with compassion and wisdom. You lead the ......
Prompt Explanation: The AI was prompted to take on a persona/role and complete a given task within a defined environment, using a template to specify the role, task, and environment.
{Persona/Role}
{Given Task} {Defined Env.}
⏰ When is this relevant?
A bank wants to understand how small business owners from different industries might react to a new business credit card offering with unique perks (e.g., flexible spending limits, industry-specific rewards, and digital-only account management). The team wants to simulate realistic customer interviews using AI personas for three segments: independent retailers, tech startups, and local service providers.
🔢 Follow the Instructions:
1. Define audience segments: Create three AI persona profiles representing each business type. Example:
• Independent retailer: 42, owns a family-run clothing boutique, values local relationships, moderate tech adoption.
• Tech startup founder: 29, runs a SaaS business with rapid growth goals, highly tech-savvy, values flexibility and scalability.
• Local service provider: 51, owns a plumbing company, practical, cost-conscious, prefers simple financial products.
2. Prepare prompt template for persona simulation: Use this format for each simulated interview:
You are simulating a [persona description].
Here is the new business credit card: "[Insert product summary and key perks here]"
You are being interviewed by a bank product manager.
Respond honestly and in character, using 3–5 sentences.
First question: What is your first impression of this business credit card?
3. Generate initial responses: For each persona, run the prompt through the AI model to get several (e.g., 5–10) simulated responses, varying the wording slightly for realism (e.g., “What stands out to you?” or “Would this card interest you?”).
4. Add follow-up questions: Based on the initial answers, ask 1–2 follow-ups such as “What would make you more likely to apply?” or “Are there any concerns or missing features?” Generate responses as a threaded conversation for each persona.
5. Tag and group responses: Review the interviews and tag key themes (e.g., “needs digital features,” “concerns about fees,” “likes industry rewards,” “prefers in-person support”). Group similar responses together for pattern analysis.
6. Compare between segments: Summarize which perks and pain points are most frequently mentioned by each business segment. Note which customer types show excitement, hesitation, or apathy toward the new card.
🤔 What should I expect?
You’ll get a clear, segment-by-segment view of which features and messaging resonate with different business owners, what potential objections or questions could arise, and which groups are likely to be early adopters or need more education. This enables targeted marketing, product refinement, and prioritization of real-world follow-up with the most strategically important customer types.



